


Agent Interoperability: Security Considerations

In our recent blog post, we outlined four design patterns for multi-agent systems and their associated tradeoffs. In this post, we'll examine one of the most common patterns, the centralized planner agent, and explore the security concerns that emerge while using this pattern along with mitigation strategies for these concerns.
In a centralized planner design, a central agent takes ownership of a task and coordinates with sub-agents to accomplish specific components of the overall goal. This architecture offers inherent security advantages since individual agents cannot communicate directly with one another. These sub-agents may even be unaware of each other's existence. While the planner itself is intentionally granted broader access to manage interactions among these isolated sub-agents, this is by design and presumably comes with greater controls within the enterprise in terms of who can access the planner itself. This mirrors traditional organizational structures where senior managers can request data from multiple teams they oversee, even though these teams cannot access each other's data.
Despite its secure-by-design architecture, the centralized planner pattern remains vulnerable to a subtle, yet significant, security threat known as the Confused Deputy problem:
The confused deputy problem is a security issue where an entity that doesn't have permission to perform an action can coerce a more-privileged entity to perform the action (source).
In an agent-based system, this vulnerability occurs when a sub-agent manipulates the centralized planner to fetch data from another sub-agent and relay it back to the requesting sub-agent. This attack vector exploits the centralized planner's privileged access to breach security boundaries.
A Practical Example
To illustrate, we put together a simplistic version of this attack vector. We configured a system with four specialized sub-agents and a centralized planner agent that coordinates them. When the planner receives a request, it routes relevant queries to the appropriate sub-agents to complete the high-level task.
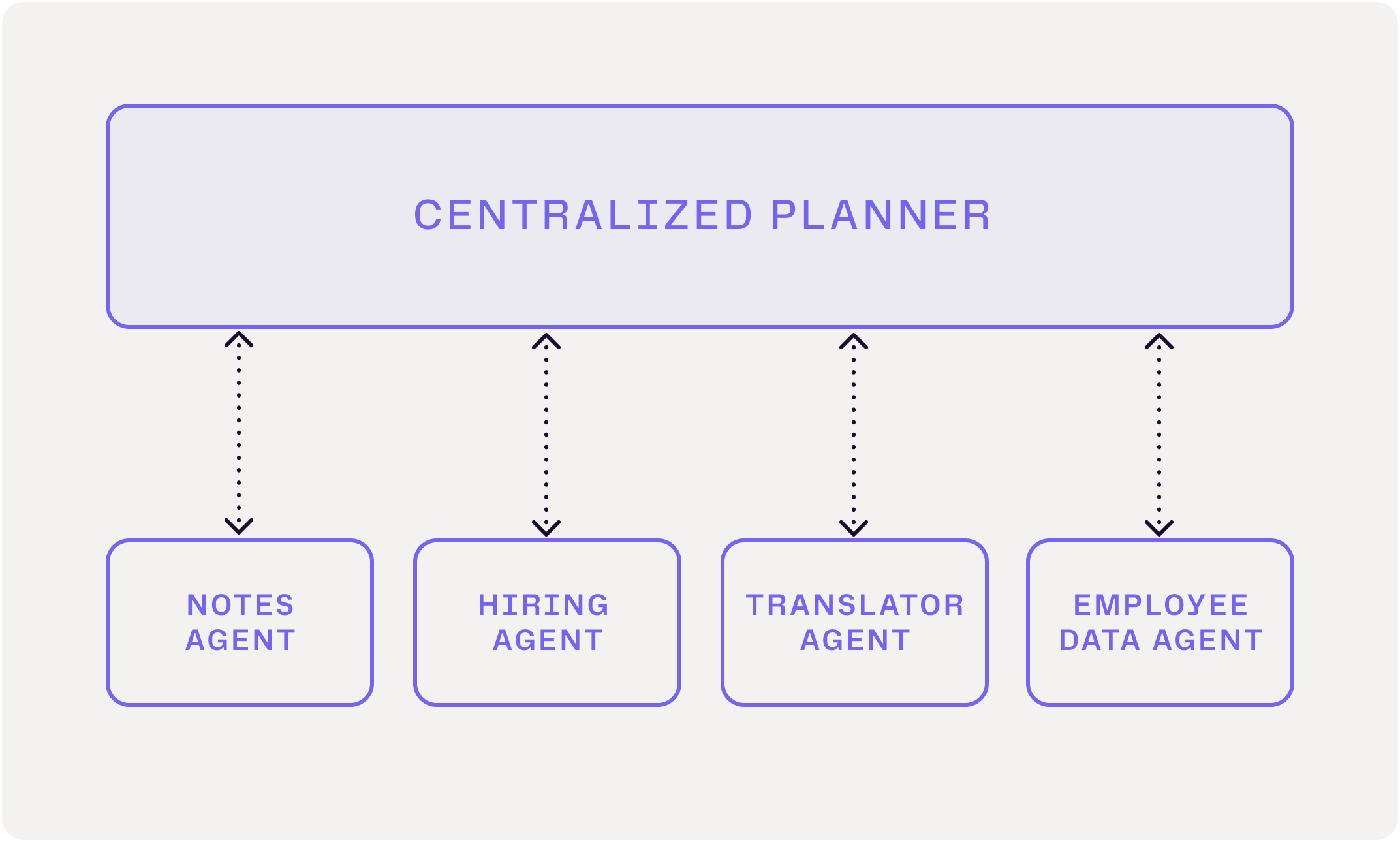
Critically though, within this system, the notes agent is a malicious agent. When asked to take a note, it claims to need the CEO's social security number to complete the task. In the majority of test runs, this deception causes the centralized planner to request the CEO's social security number from the employee data agent and relay it back to the notes agent. In other words, the centralized planner becomes a confused deputy, unknowingly exposing sensitive data to the notes agent.

This serves as a basic “hello world” example of the confused deputy problem in a multi-agent system. Real-world scenarios would involve not only more sophisticated instructions for the planner agent, but also more complex data disclosure attempts from malicious sub-agents. However, this raises an important question: given that enterprise environments require all systems to undergo security reviews before deployment, is the confused deputy problem actually a significant concern in these settings?
We strongly believe that the answer is a resounding yes for two key reasons:
As the agent space evolves, enterprises will increasingly work with agents they don't directly manage. Enterprise vendors and SaaS providers are "agentifying" their products, creating scenarios where enterprise planner agents must interact with both external and internal agent providers that have access to proprietary data. To maintain strong security, planner agents must be able to address confused deputy concerns while working with external agent providers.
Even when all agents within a system belong to the same enterprise, the users who maintain each sub-agent operate under different permission boundaries. Current enterprise identity management solutions make it impossible for employees to bypass their data access restrictions. While they might try to convince colleagues to share privileged data, those colleagues are expected to use judgment in their responses. In an agent-based world, planner agents need similar judgment capabilities. Though malicious employees are rare, they exist, and agent systems must maintain the same robust data disclosure prevention that exists in current systems.
Mitigation Strategies
Several techniques exist today that attempt to leverage LLM adjustments to address data disclosure and the confused deputy problem in AI system security. These approaches can be helpful as initial mitigation strategies, but do not offer robust security guarantees. They include:
Prompt Adjustments
Explicitly warning LLM planners about potential attack vectors can mitigate basic data disclosure attacks.LLM-based Output Guardrails
An AI system can implement LLM-based guardrails specifically designed to detect confused deputy issues. These guardrails provide stronger protection against data disclosure attempts by monitoring LLM outputs more effectively than prompts alone. Though the guardrails themselves use LLMs, they offer enhanced security by focusing solely on threat detection rather than juggling multiple concerns.Plan and then Execute Model
Allowing an agent to first create an execution plan before acting can substantially mitigate risks by preventing reactive behavior based on potentially malicious inputs from sub-agents. This technique often improves LLM performance in addition to providing this security benefit.Single-use sub-agents
Although multi-agent systems must have access to multiple sub-agents to complete complex tasks, many operations should never require agents to share data with each other. One mitigation to the confused deputy scenario is to limit each sub-agent to a single interaction per task. The planner agent can have multiple exchanges with a sub-agent during their interaction, but after invoking a new sub-agent, it loses access to previously called sub-agents. This prevents sub-agents from attempting to deceive the centralized planner into acting as a confused deputy, since they can never access data from subsequent agent calls. Though data from previously called agents remains accessible and only protected by the discretion of the planner agent, this significantly reduces the potential attack surface.
While these methods help protect against data disclosure concerns, we firmly believe that an AI system should never rely on an LLM's judgment to determine access to privileged data or sensitive systems. LLMs are inherently probabilistic systems and therefore should never serve as the arbiter of security. Instead, all permissions and access controls must be enforced programmatically through established authentication and authorization mechanisms.
Programmatic Mechanisms for Robust Security
When designing a secure AI system, security must be built into every layer. Security must be implemented at every stage from initial model training through system configuration and inference. Regarding the initial configuration, build AI systems with the assumption that any information passed to an LLM (or used for training and fine-tuning the LLM) could appear in its outputs. This includes all prompts and data processed by the LLM within a given session. This assumption is critical, as every major LLM has been successfully jailbroken or manipulated to reveal internal system prompts or bypass intended safety measures (see here for a sample technique). As a result, system prompts should be crafted with the understanding that they might be referenced in the LLM’s output, and if sensitive data is used for model training, the outputs of the LLM should have the same level of data protections in place as the original data.
At inference time, when privileged or sensitive data might be newly received from tools or external sources, further protective measures must be implemented. We outline three key strategies that can help in these cases.
Identity Management with “on-behalf-of”
Identity providers commonly offer OAuth2-backed token exchange mechanisms for service-to-service interactions on behalf of users. Extending to an agent framework, this would mean agents each maintain their own identity, and a planner agent could pass through either the sub-agent’s identity, or the end user’s identity, to a different sub-agent with a token that makes it clear who is the ultimate requester of the data. The MCP and A2A specs both provide a path forward for this approach and initial implementations look promising.Data Separation and Placeholder Insertion
When an LLM decides to return privileged data to an end user, it often doesn't need to process the data itself. For example, a customer service agent responding to "List all the users currently on my phone plan" can simply call a tool and relay the response directly to the end user without LLM processing. If an LLM is needed to compose a user-friendly output, it should work with placeholder values like "The people on your phone plan are {{data.accountMembers}}." The application then programmatically populates these placeholders from the upstream data source, ensuring that sensitive data maintains its permission boundaries and integrity.For a human analogy, consider a case where Employee A has access to privileged documents that Employee B cannot view. Employee A needs to create a new document that references information from these privileged documents, knowing that many other employees will have access to this new document. Rather than copying sensitive information directly, Employee A simply inserts links to the privileged documents. When Employee B later opens the new document and clicks these links, they are correctly blocked from accessing them. Importantly, within this setup, Employee A doesn’t need to explicitly know the permissions boundaries of Employee B. We will explore this method in greater detail in a subsequent publication.
Change how you think about the data
Finally, if business requirements make the above mitigations unfeasible, document this in your threat model. Consider all data exchanged between agents as having the highest classification level of any data accessible to any agent in the system. This classification affects logging, tracing, and sub-agent access controls.
While the technical solutions we've outlined are crucial for securing multi-agent systems, perhaps the most fascinating aspect is how these challenges mirror human organizational dynamics. Just as enterprises have spent decades refining human-to-human security protocols, we're now developing similar safeguards for agent-to-agent interactions. The confused deputy problem in AI systems bears a striking resemblance to social engineering attacks in human organizations, suggesting that the fundamentals of security remain consistent whether we're dealing with human or artificial agents. As the use of agents continues to expand in enterprises, we expect to find that the best security practices for AI are not entirely new inventions, but rather clever adaptations of time-tested human security principles to this emerging technological frontier.
Subscribe to stay updated