
Agent Interoperability Design Patterns

Introduction
In large enterprises, the adoption of AI-powered agents is growing rapidly, but agent interoperability remains a major challenge. Different teams deploy agents targeting specific portions of the business, but how these agents work together to accomplish larger goals remains undefined. Without a paradigm for agent interoperability, agents will only be able to provide point wise improvements to business processes and not higher value functions.
We view an agent as an AI system that is defined with a specific scope of instructions or context, and a set of tools that it has access to use. It is able to perform multi-step workflows, dynamically deciding which tools to leverage when. Agents can be triggered through various mechanisms including chat threads, API calls, or more sophisticated protocols like MCP. As enterprises build specialized agents to solve specific business needs, more sophisticated problems become tractable with multiple discrete agents working together.
As a motivating example, in a supply chain, different teams might deploy AI-powered agents for specific tasks:
Inventory Management Agent: Optimizes stock levels to reduce waste and prevent shortages.
Logistics Agent: Finds the most efficient shipping routes and schedules deliveries.
Procurement Agent: Automates supplier negotiations and purchase orders.
Without interoperability, each agent improves its own process (point-wise improvement), but they don’t work together. For example, the inventory agent might flag low stock, but if it doesn't communicate with the procurement agent, orders might be delayed. Similarly, the logistics agent might find the fastest route, but if it's unaware of real-time supplier delays, shipments could still be late.
With interoperability, these agents could collaborate—adjusting procurement based on shipping constraints or dynamically optimizing inventory based on logistics bottlenecks—leading to a more resilient and efficient supply chain.
The challenges for agent interoperability include handling security concerns regarding data sharing between specialist agents, implementing clear observability and failure recovery, and correctly architecting these systems to most successfully be able to carry out goal oriented tasks. Some of these concerns are addressed by protocols like MCP, or Google’s A2A, but the general design patterns have not yet been explored in depth. Complexity is increased due to the fact that these agents are oftentimes managed by different engineering teams.
At Distyl, we work with the largest companies in the world, building AI native solutions that solve complex business use cases. We have observed several patterns on how disparate agents can cooperate in a secure and scalable way. This blog post is the first in our series on Agent Interoperability, where we will share our learnings on AI systems design and the patterns that work at scale. Each pattern has its applicable use cases. As with software engineering, there are always tradeoffs to consider, and which solution is applicable is highly dependent on the problem at hand.
At Distyl, our approach towards agentic solutions is informed by two key frameworks:
Agents as employees
Deploying an agent into production is more similar to onboarding a new employee to your team than deploying a piece of new software. When a team onboards a new employee they need to teach that employee their business context, grant them access to the systems they need for their role, and train them in how to perform their business function. The same holds true for an AI system - as it gets onboarded, it continuously improves until it successfully supports the business need.Software as an inspiration
Over the past 60 years, the software development industry has developed robust patterns for managing, testing, and deploying software at scale in a secure and maintainable manner. We look to the world of software for inspiration in terms of how to design agentic systems that allow us to safely, and confidently, deploy agentic solutions.
These two frameworks model the lifecycle and best practices for a single agent deployed in a customer’s environment, but also provide perspective on how multiple agents can collaborate together on even more complex uses cases.
Forms of Collaboration
Imagine each agent within an enterprise as an employee with specialized skills and knowledge, each tasked with handling a specific aspect of a larger objective. To achieve success, these agents must communicate, share information, and coordinate their actions toward a common goal.
Just as human teams adopt different collaboration strategies depending on the business use case, so too AI agents must also establish structured mechanisms for interoperability. Without a framework for seamless interaction, these agents risk working in isolation, delivering only fragmented, incremental improvements rather than driving meaningful, system-wide transformation. Below are several, non-mutually exclusive, models of how this collaboration is achievable.
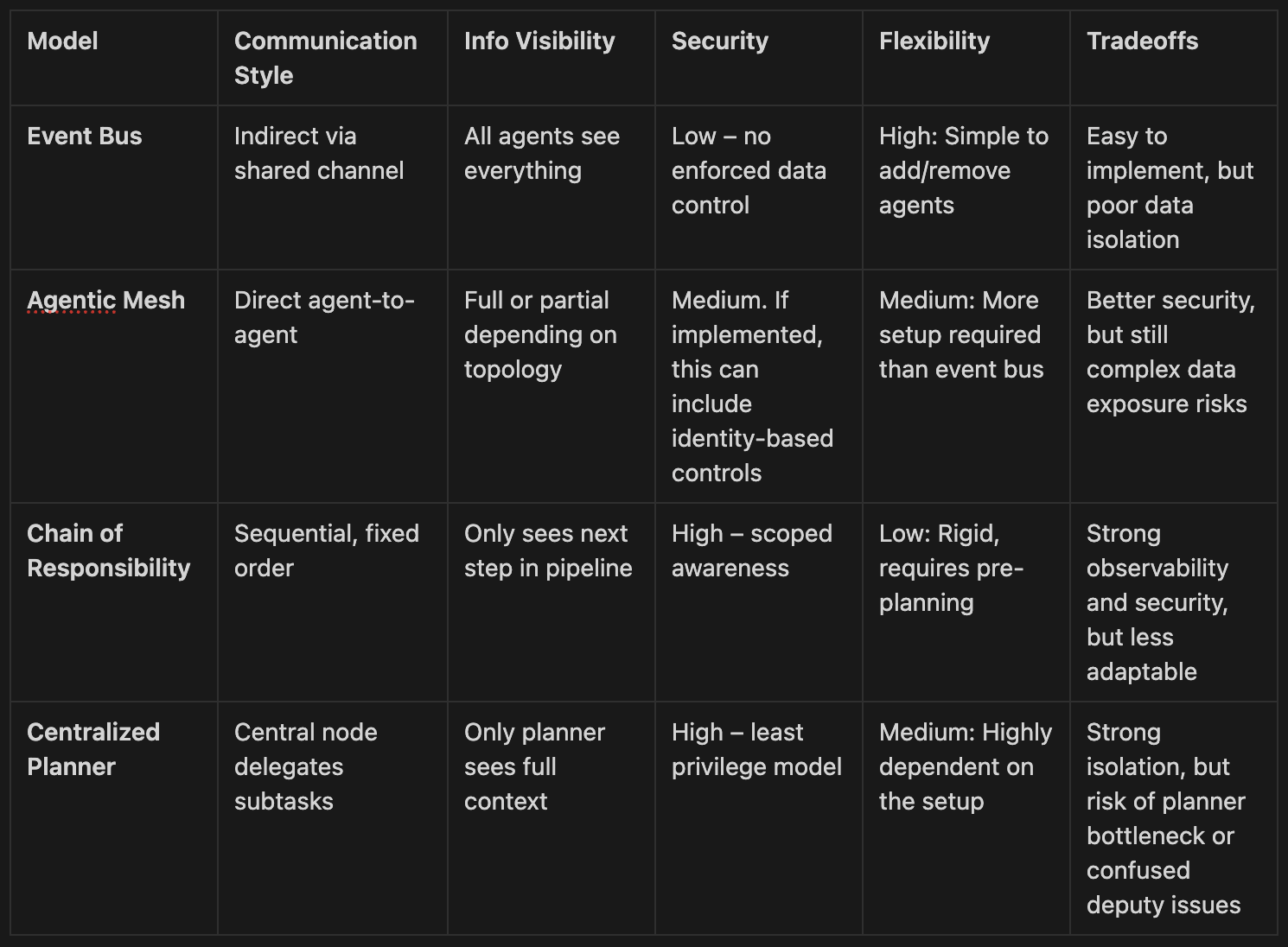
Event Bus

The first model for collaboration is a “raise hands” system. A team sits in a room, a problem statement is presented, and each individual on the team provides their unique contribution to the solution, dependent on their background and knowledge. The event bus model includes scenarios where actors communicate indirectly with one another via a shared communication channel. Examples of event buses in the world of human interactions include in person meetings, email threads, chat groups, and messaging boards. A crucial component of this model, is that all information is shared between all participants in the conversation. An individual may withhold some knowledge that they have, but there is no mechanism in place that enforces this.
This model extends to agentic systems. At Distyl, we built out a system following this model that uses Slack as an orchestration framework. Multiple independent agents have access to a centralized slack channel, and receive new messages via Slack’s webhooks. Each agent has complete context on the whole conversation and is able to contribute to the conversation when relevant questions are asked.
This pattern excels in its simplicity to implement. No specialized configuration is required to get agents communicating with one another, rather, onboarding a new agent involves adding them to the shared communication venue. The downside with this approach is that it sacrifices the ability for individual agents within the system to gate access to specific information from specific actors within the system. This pattern is only suitable for cases where data sharing concerns are minimal, such as within a single business context at an enterprise, where knowledge can safely be shared across agents.
Agentic Mesh
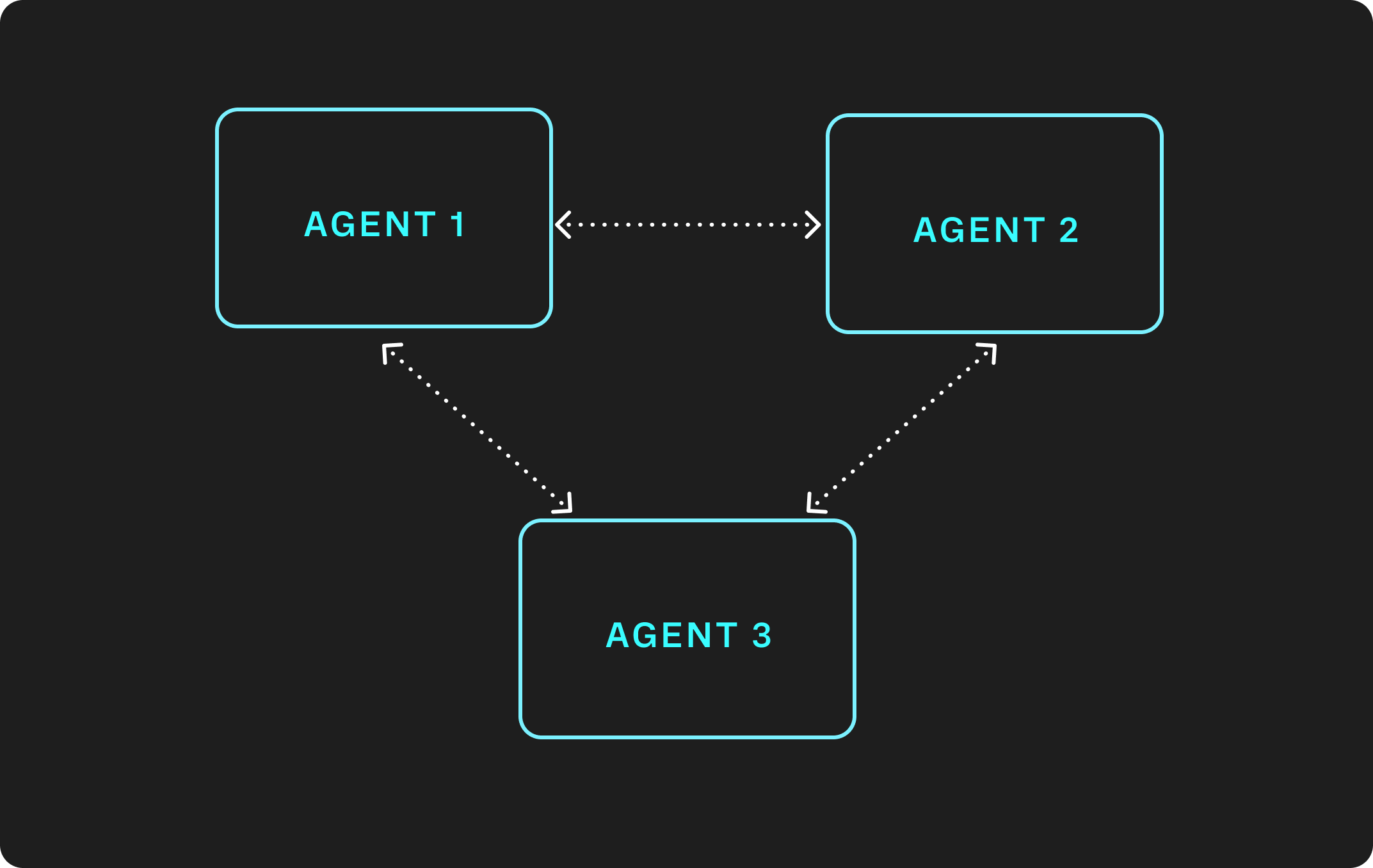
A similar pattern to the event bus is an agentic mesh. This pattern is similar to the event bus in that all information is shared between all participants in the conversation, but the method of sharing information differs. Whereas in an event bus architecture, information sharing between agents happens via a shared medium, in an agentic mesh communication occurs through direct inter-agent communication. In the human world, an example of a mesh is where each employee on a team has the phone number of all of their teammates, and calls a specific teammate when their expertise is required.
Many examples of mesh topologies exist within the world of distributed systems. These include IoT networks, database nodes, and computing clusters. Some of these systems implement a fully connected mesh where each node is connected to the entire system, whereas others use a partially connected mesh to improve resilience.
When we think about creating an agentic mesh topology, there are two different forms that this can take. The first is a fully connected direct topology where every agent has the ability to interact with all other agents in the mesh via a direct interface (Think API calls, MCP, tool calls). This is a decentralized, highly connected, system that has immense power in terms of accomplishing tasks, but comes with the risk that all data is now shared between the different agents. A second is a partial mesh where each agent has access to a subset of other agents within the topology. The main differentiating factor between an agentic mesh and an event bus is that since communication between agents is direct, there is an opportunity to implement identity based security controls that attempt to control what information is safe to disclose to a particular agent. We will explore in a subsequent blog different strategies to mitigate data disclosure and call out what risks still remain.
Chain of Responsibility

A third pattern of human interaction for accomplishing goal oriented tasks is a chain of responsibility (CoR). A team is assembled where each person on the team has a distinct task that they know how to perform, and knowledge of who they should inform when they have completed their task. Real world examples include production lines in factories, and routing systems.
More so than a mesh architecture, the chain of responsibility model is highly used in the world of software engineering. Nearly all web servers support a CoR model using things like handlers or middleware. UI frameworks like React process events through single responsibility hierarchies, and ETL data pipelines process data in discrete steps.
This pattern is good for rigid processes with clearly defined stages. The advantage of this pattern is that security controls are tight from the outset as each agent in the process only has awareness of the next agent in the pipeline. Additionally, this type of system is easy for humans to reason about, and allows for simpler observability solutions as there is a distinct input and output for each step. The downside is that setting up an agentic pipeline requires pre-planning by either a human, or an agent, which makes adapting the pipeline to a new set of tasks a higher cost operation.
Centralized Planner

A fourth pattern for human interaction is one where a centralized manager takes on ownership of a task and reaches out to individuals within their network for information needed for subtasks. This model of communication is often preferred in areas where access to information or tooling is heavily gated. A key feature of this mode of communication is that individuals other than the manager have no insight into the higher level goal that their piece of information is contributing towards. This comes with a disadvantage in that the manager may need to ask followup questions to their network to clarify what the request is, but the benefit is that information sharing follows the principle of least privilege.
An example of this in software design is Distributed Query Execution with frameworks like MapReduce and Apache Spark. Within these systems, a central controller node takes in a high level task, and breaks it down into subcomponents. The controller then distributes the work to worker nodes that each accomplish the specific task that was assigned to them without a broader awareness of the end goal of the system. Only the controller node is aware of the entire system and has access to the workers for orchestration.
This model attempts to balance providing agents with enough power and visibility to accomplish interesting tasks, while still keeping security and data isolation a centralized focus of the design. In a subsequent post we will dive deeper into how to architect this pattern in a way that avoids using the centralized planner as a confused deputy in a way that breaks data isolation.
To summarize:
The next set of blog posts will deep dive into these different models of collaboration, highlight the type of problems the design pattern is relevant to, and discuss best practices for implementing an end to end solution using the design pattern.